
手把手教你如何在观远BI中正确设置ETL的增量更新
2024年05月31日
评论数(0)慢ETL是数据分析师们经常会面临的问题。关于如何对慢ETL进行优化,也成了一项令数据分析师们颇感头疼的工作。诚然,因为ETL运行环境、处理逻辑、业务规则等因素不尽相同,需要对不同的ETL采用不同的优化策略。但这其中绝大多数的慢ETL都会普遍存在一个共性:大数据量下的全量跑批。这就是ETL运行缓慢的重要影响因素之一,也是慢ETL优化的一个主要发力点。而解决这一问题的主要手段就是——增量更新。本文会手把手教你如何在观远BI中正确设置ETL的增量更新。
什么是增量更新
想要去设置增量更新。首先肯定要理解什么是增量更新,以及增量更新作用的阶段。
1、定义
增量更新是指仅更新自上次更新以来发生变化的部分数据,而不是对整个数据集进行更新。这种更新方式可以大大减少数据处理的时间和资源消耗。
2、作用阶段
增量更新的设置一定是发生在首次全量跑批之后。全量跑批的结果会作为下次增量更新时的历史数据,合并增量数据的处理结果作为最终的输出。
增量更新设置方法
许多数据分析师会以为ETL从功能上并不支持增量更新。观远BI的智能ETL虽没有像数据集一样,直接提供增量更新的配置项和清晰而明确的增量更新逻辑,但其功能上是完全支持增量更新的。不过还有很多分析师不知道具体该如何操作。
下面我们按照上文“作用阶段”中对于增量更新出现的过程描述来进行增量更新ETL的实现。
1、全量ETL搭建与运行
首先第一步,我们按照正常的业务处理逻辑,搭建一个基于全量数据的ETL处理流程,如下图所示。其中处理逻辑部分替换为实际的数据处理规则,这里仅仅做了简单的数据关联。
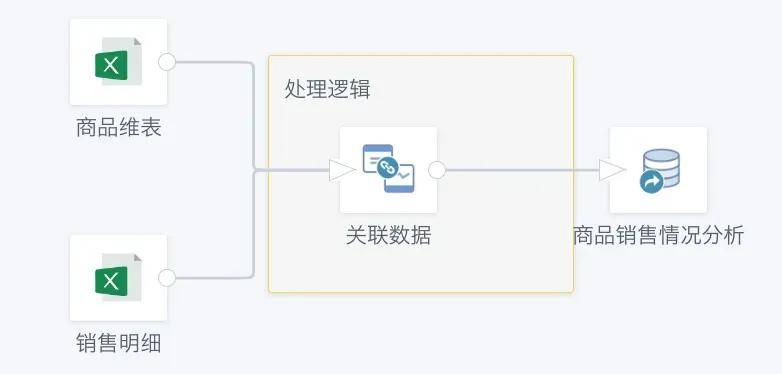
搭建完成后需要将ETL至少运行一次,目的是为了拿到输出结果作为接下来增量更新的输入数据集。
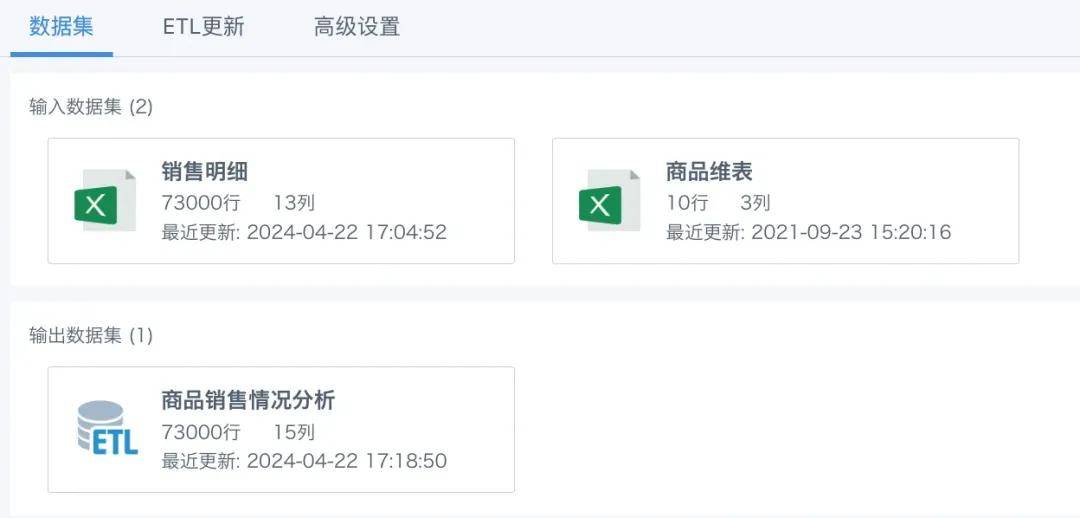
2、增量ETL改造
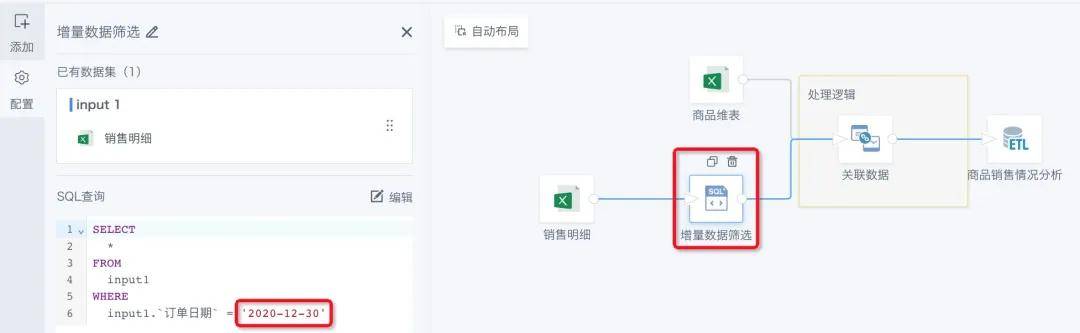
接下来就要进行关键的增量改造了。首先进入之前的ETL编辑界面,在原本的全量输入数据集后通过SQL算子增加筛选逻辑。目的是筛选出相较于上次运行时,新产生的增量数据。
在提供的案例中,原本的数据截止是2020-12-29,数据更新后增加了2020-12-30的数据,因此在筛选逻辑中直接选出了2020-12-30的数据。这里可以根据实际的业务需求改为动态日期参数,比如通过current_date()来拿到当前的日期,只对当前日期的数据进行处理。
通过上面的处理我们成功获取到了增量数据,并对增量数据进行了与之前全量数据相同的数据处理。这样处理完是不是还少了些什么?没错!我们缺少了对于之前全量数据跑批结果的处理。
接下来我们需要添加一个输入数据集算子,用当前ETL的输出数据集同时作为输入数据集。这么做的目的是将上一次的输出结果作为本次的历史数据输入。再将历史数据与上面处理的增量数据进行行拼接,最终输出。

以上就是ETL增量更新逻辑的简单实现。
数据的增量更新是ETL过程中至关重要的一环。然而,很多时候却被我们忽略从而导致慢ETL的产生。希望本文能够帮助大家学会如何灵活设置增量更新,最终达到降本增效的目的。