 老高的购物篮分析
老高的购物篮分析
公告
“啤酒与尿布”是一个真实的故事,发生在1990年代的沃尔玛大卖场,代表卖场的购物篮商品之间存在着某种特定的关联关系,挖掘并利用这种关联关系,可以使得实体零售门店充分;了解顾客的购物场景,为选品与品类管理、定价与调价、促销策略及评估、关联陈列、顾客行为聚类等提供了有效的数据依据。
我在2008年撰写了《啤酒与尿布-神奇的购物篮分析》(清华大学出版),开辟本专栏,是为了与大家探讨实体门店购物篮管理的理念、计算方法及案例,以及能够与相关软件企业合作,开发相关应用软件产品
MP:13901022781 微信同号
统计
今日访问:1606
总访问量:779285
Apriori算法解析(以R语言为例)(二)
2023年08月31日
评论数(0)对Groceries数据进行关联分析
# size函数和itemFrequency函数都是arules包中的函数,前者是计算购物篮中出现过的商品次数,后者是为了计算每种商品出现的次数(频率)
>basketSize<-size(Groceries) # 计算Groceries的购物篮商品系数
> sum(basketSize) # 显示如下:
[1] 43367 # 说明在9835个购物篮中,169个商品共出现了43367次;
> itemFreq<-itemFrequency(Groceries) #计算Groceries中169个商品在购物篮中出现的频次
> itemFreq[1:5] #列出交易数据中五个商品出现的频次分布。
# 显示结果为:
frankfurter sausage liver loaf ham meat
0.058973055 0.093950178 0.005083884 0.026029487 0.025826131
# frankfurter(法兰克福香肠)出现的频次为0.05897%,sausage(香肠)出现的频次为0.0935%,依次类推;
# 这里可以理解为频次对应了商品的购物篮渗透率;
>itemFrequencyPlot(Groceries,support=0.1) #对Groceries数据库按照支持度为0.1(10%)的数据集合绘图,结果如下图3-3:
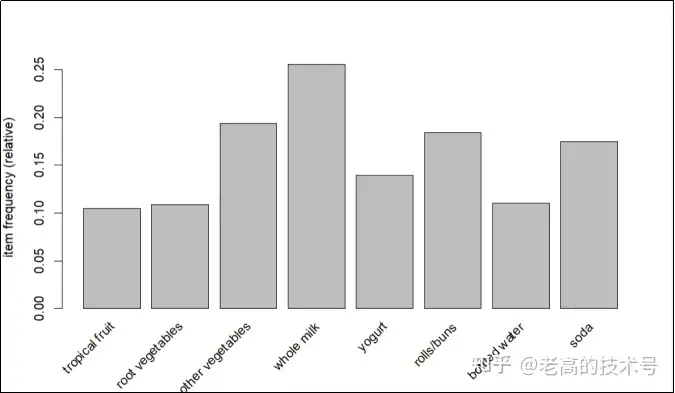
图3-3 支持度为0.1的商品频次分布图
# 在图3-3 中,出现频次最高的购物篮商品为Whole milk(全脂牛奶),数值大于0.25,支持度最低的商品为tropical fruit(热带水果)、bottleed water(瓶装水),均为0.1。
>itemFrequencyPlot(groceries,topN=10,horiz=T) #按照支持度Top 10的频次排序绘图,结果如图3-4:
# 在Groceries数据库中,出现支持度频次的商品排序依次为whole mike(全脂牛奶)、other vegetables(其他蔬菜)、rolls/buns(圆面包)、soda(苏打水)等,这个图表明在该超市中,最受顾客关注的商品排列顺序(商品的购物篮渗透率)。

图3-4 支持度ToP 10的购物篮商品频次图示
>total.rules <- apriori(Groceries,parameter = list(support=0.01,confidence = 0.05)) # 按照支持度=0.01、置信度=0.05对Groceries数据进行数据过滤;
>print(summary(total.rules)) # 将过滤结果打印出来,
# 如图3-5所示,过滤结果共有541条规则,其中购物篮系数(含左侧+右侧)的分布为1个的购物篮为28个、2个的购物篮为417个、3个的购物篮为96个。
# 列出了过滤的关联规则购物篮系数四等位数分布,均值为2.126,以及规则的关联分析指标分布。
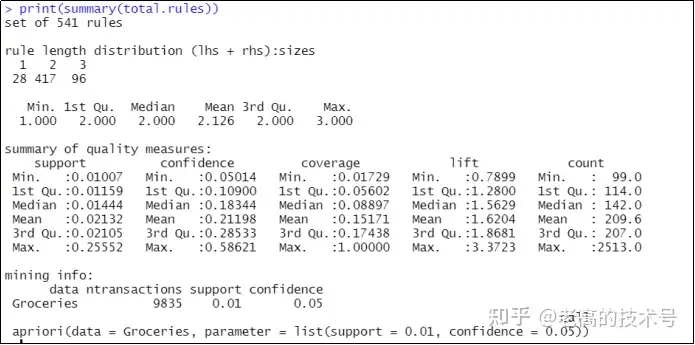
图3-5 按照特定条件的关联过滤结果图示
>soda.rules <- subset(total.rules,subset=rhs %pin% "soda") #按照上述条件的支持度、置信度阈值条件,寻找购物篮的后件(被关联商品)是“Soda(苏打水)”的关联规则;
>inspect(soda.rules) # 将后件含有soda的规则打印出来,如下图3-6所示:
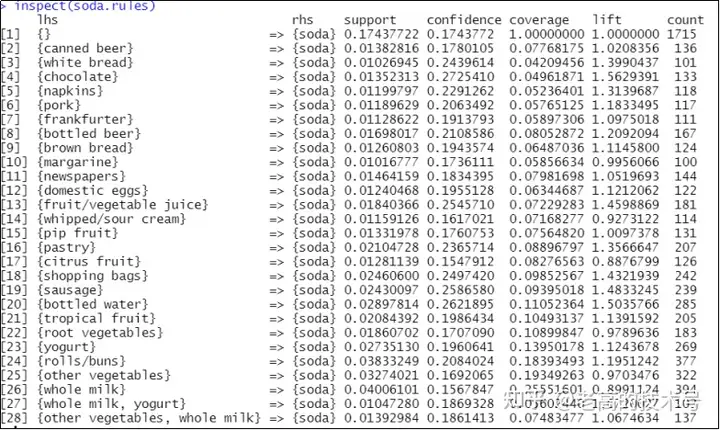
图3-6 特定条件后件为“soda”关联规则图示
# 共生成28条购物篮后件是soda的关联规则,以图3-6 第一行为例,购物篮中只有soda 的规则支持度是0.1743、置信度为0.1743、(规则对于总数据集合)覆盖率为1.00、提升度为1.00、共有购物篮1715个。
# 图3-6第二行说明购物篮中商品前件为canned beer(罐装啤酒)与soda的支持度为0.0138、置信度为0.178、覆盖率为0.077、提升度为1.02、共有购物篮136个;其他数据以此类推。
>groceries_basket<-Groceries[basketSize>1] # 寻找Groceries中购物篮系数大于1的项目集合;
>dim(groceries_basket) # 输出结果如下:
[1] 7676 169 #共有7676个购物篮中商品系数大于1(即购物篮中商品多于一个),由169个商品完成。
>grocery_rules<-apriori(Groceries,parameter=list(support=0.02,confidence=0.25,minlen=2)) #寻找Groceries数据库中满足支持度0.02、置信度0.25,Minlen=2(购物篮系数)的规则。
# 输出结果表明有 196条记录满足这个条件。
> yogurt_rules<-subset(grocery_rules,items%in%c("yogurt")) # 在上述规则满足的频繁项集中寻找“Yogurt”(酸奶)出现的购物篮;
# items %in% c("A", "B")表示 lhs+rhs的项集中,至少有一个item是在c("A", "B"), item = A or item = B。
# 如果仅仅想搜索lhs或者rhs,那么用lhs或rhs替换items即可。如:lhs %in% c("yogurt")
# %in%是精确匹配、%pin%是部分匹配,也就是说只要item like '%A%' or item like '%B%',同时可以通过 条件运算符(&, |, !) 添加 support, confidence, lift的过滤条件。
> inspect(yogurt_rules) # 按照定义的规则输出如下结果:
lhs rhs support confidence coverage lift count
[1] {yogurt} => {other vegetables} 0.04341637 0.3112245 0.1395018 1.608457 427
[2] {yogurt} => {whole milk} 0.05602440 0.4016035 0.1395018 1.571735 551
# 共生成有二条规则:
1、{酸奶=>其他蔬菜},支持度为0.043,置信度为0,311、覆盖率为0.139、提升度为1.60、共有购物篮427个。
2、{酸奶=>全脂牛奶},支持度为0.056、置信度为0.40、覆盖率为0.139、提升度为1.57、共有购物篮551个。
>last.rules <- apriori(Groceries,parameter = list(support=0.025,confidence=0.05)) # 按照支持度=0.025、置信度=0.005 对Groceries数据库寻找关联规则
>print(summary(last.rules)) # 显示如下关联规则:
set of 96 rules # 共有96条满足条件的规则
rule length distribution (lhs + rhs):sizes # 关联规则的购物篮系数分布
1 2
28 68
# 购物篮系数为1的规则共有28条、购物篮系数为2的规则共有68条